Databricks Migration from a Leadership Perspective: How to Get Started
For three days, business has been waiting for answers.
The reports are ready, but no one is sure which numbers to trust. Who is the data owner? How is this KPI defined?
In data-intensive organizations – banks, insurance companies, telcos – this is not an unusual situation. Massive amounts of data are not a competitive advantage on their own. They become risk, cost and organizational tension if there is no operating model that can turn data quickly and securely into business decisions. In regulated environments, data is not only an asset – it is also a compliance risk.
What Does the C-Level See?
At executive level, the questions are rarely technical. It’s not about Spark or SQL, but rather:
- How long does it take to get a data-driven answer to a business question?
- How much can I trust the numbers (data quality, definitions, auditability)?
- How much does all this cost (infrastructure + human effort + hidden operational costs)?
- How secure and compliant is it (GDPR, DORA, audit, access management)?
If there are no clear answers, “data-driven operations” become a bottleneck instead of an accelerator.
The Solution: Databricks
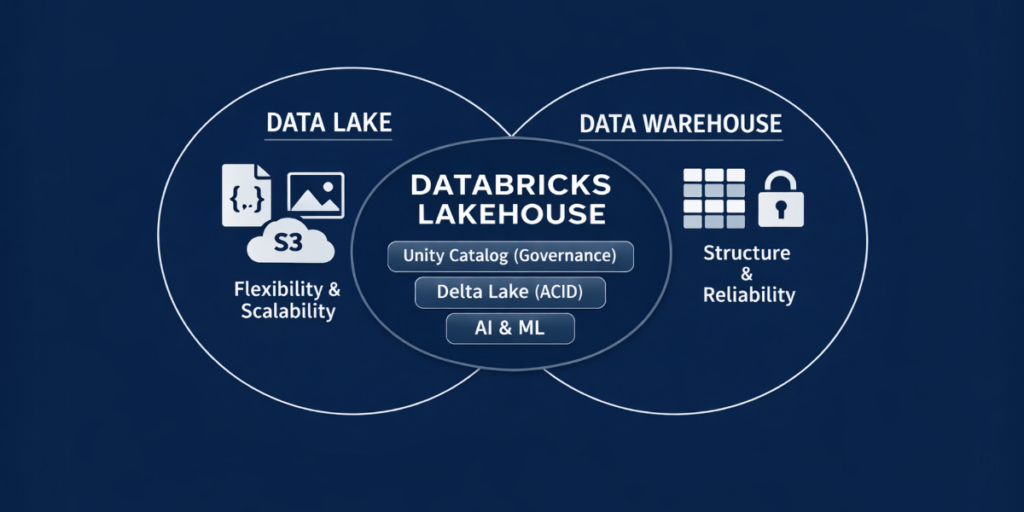
One possible response to these challenges is Databricks, the world’s first Data Intelligence Platform built on modern Lakehouse architecture. It eliminates data storage silos by combining the reliability and structure of data warehouses with the flexibility and scalability of data lakes. There is no need to choose between flexibility and control: structured and unstructured data can be managed together, while maintaining traceability and data quality.
Databricks became a market standard within a few years because it:
- Eliminates storage and processing silos: ETL, storage, BI reporting and machine learning can be managed from a single interface.
- Uses open standards: No vendor lock-in. Built on Delta Lake and Apache Spark, your data remains yours, in open format.
- Includes built-in governance: With Unity Catalog, centralized control over organizational data assets supports DORA and GDPR
Developers also love it because it dramatically increases productivity:
- Multi-language support within the same workspace.
- Real-time collaborative coding, versioning and interactive visualization.
- Serverless computing that scales automatically with data volume.
Where Does Databricks Migration Fail – and How Should You Start?
Many Databricks programs fail because they are launched as IT projects, while in reality they should build business capability. Typical pitfalls include the following:
- There is no clear business focus
- Governance is added as an afterthought
- Implementation is treated purely as an IT project
- Collaboration is unclear between internal and external stakeholders
Our experience shows that Databricks initiatives succeed when:
- A business-relevant use case exists from the beginning
- Success is clearly defined (time, quality, risk, cost)
- Governance is part of the foundation
- The organization does not become dependent on external parties long term
How to get started? This approach typically works:
- Start with 1–2 business-critical use cases with measurable success (e.g. fraud detection accuracy, customer value segmentation, network failure prediction).
- Define executive KPIs early (lead time, quality, cost, risk).
- Clarify decision rights: data ownership, definitions, access, change management.
- Avoid migrating everything at once. “Big bang” rarely works, especially in regulated industries.
Databricks Consulting at DSS: What Do We Do Differently?
As registered Databricks consulting partners, we treat Databricks implementation not as a “platform rollout,” but as business transformation. Key elements of our approach include:
- Shift-left governance: Quality, access management and control are embedded from pipeline design stage.
- Fixed-price pilot with real use case: Tangible business results within 3–4 months (e.g. fraud detection, claims analytics), with controlled risk.
- Data product mindset: Data as a reusable, ownership-based product with measurable ROI.
- Knowledge transfer, not dependency: The goal is long-term internal capability.
This is how our implementation process looks in practice:
- Strategy and target architecture review: Prioritizing use cases, MVP scope, governance principles up front.
- Controlled platform foundations: Secure workspaces, network isolation, IaC, cost control.
- Shift-left governance & DataOps: Unity Catalog, access control, CI/CD, data quality and testing standards built in, not as an afterthought.
- Iterative development and migration: Gradual migration instead of a „Big Bang”, with measurable results.
- Operations and optimization: Monitoring, incident handling, cost and performance finetuning.
Why Does This Matter at Executive Level? Because Databricks becomes not „just another platform” but
- Faster time-to-insight
- Fewer data disputes and manual workarounds
- Auditable and transparent operations
- Lower long-term operational risk
The fixed-price pilot approach enables tangible results within 3–4 months, with controlled risk – not just promises.
Finally, a Short Executive Checklist…
If you are considering Databricks or another modern data platform, ask the following questions:
- Where is slow data the most expensive?
- Where does most manual data handling occur?
- Where are compliance and audit risks the highest?
- What result would be visible at executive level within 90 days?
If you have all the answers, the technology decision becomes much easier.
In data-intensive industries (especially banking, insurance, telecoms), the data platform question is fundamentally about business speed and control. Databricks can be a powerful tool – but the real value comes when implementation is built around business goals, measurable outcomes and operating frameworks.
Is your company considering Databricks migration? Why not discuss this over a cup of coffee?